Figure 1: Scanner: triple inheritance
E.g., when the g++ compiler detects an error or warning it displays the
full line in which the error or warning condition arose, as well as a column
indicator indicating where the condition was observed (below, a condition
where the current input line should be displayed is simply called a
`condition').
Flexc++ could use one of the following approaches to provide the required condition information:
length() to a data
member keeping track of the length of the line read so far, making
this data member's value available through an accessor (e.g.,
column()). After each newline this data member is reset to zero.
The code calling the scanner's lex member maintains a data
member holding the offset that was last returned by the scanner, as
well as a `condition vector' whose elements contain column numbers and
messages describing the nature of the conditions.
When the code calling the scanner's lex member observes a
condition it compares the offset returned by the scanner to its
own offset data member.
If the two offset values differ the source file's line that begins at the code's offset data member is read, so this line can be shown together with a column indicator and a message describing the condition for each of the lements of the condition vector. Following this, the condition vector is erased, and the scanner provided offset is assigned to the code's own offset data member.
If the two offset values are equal the scanner's
column value and the nature of the condition are added to a
`condition vector'.
This approach has the advantage of being relatively simple. A disadvantage could be that it can only be used for seekable media, or that the overhead of seeking and reading lines of the file that is processed by flexc++ is considered impractical.
The implementation of this approach is left as an exercise to the reader.
Scanner object keeps the last-read line, a column
indicator, and a reset flag, which is initially set to true and also after
reading a newline. If the reset flag is true, the column indicator is set to
0, otherwise it is updated to the length of the currently matched text. Here
is the initial section of the class Scanner, showing the new data members:
class Scanner: public ScannerBase
{
std::string d_storedLine;
size_t d_column = 0;
bool d_reset = true;
public:
...
};
Of course, the lexer won't return for all matched text, but once a rule has
been matched the posCode member is called, so this function can update the
column and reset indicators:
void Scanner::postCode(PostEnum__ type)
{
if (not d_reset)
d_column += length();
else
{
d_reset = false;
d_column = 0;
}
}
The scanner's default rule (the StartCondition__::INITIAL scanner simply
reads the initial line, and then pushes the line back onto the scanner's
queue. A simple .* will ensure that all the line's characters are
read. Having matched a line it must still be broken down into tokens, for
which the %x main start condition is used. The default (INITIAL)
scanner's rule looks like this:
.* {
d_storedLine = matched();
push(d_storedLine);
begin(StartCondition__::main);
d_reset = true;
}
Now that the line has been stored, it's time to obtain its tokens, which is
the responsibility of the StartCondition__::main start condition:
<main>{
[ \t]+ // skip white space chars.
[0-9]+ return NUMBER;
[[:alpha:]_][[:alpha:][:digit:]_]* return IDENTIFIER;
[][] return SIGNAL;
. return matched()[0];
\n begin(StartCondition__::INITIAL);
}
Identifiers and numbers are returned as tokens, square brackets are returned
as SIGNAL tokens, indicating that we would like to see the lines and
columns in which they were found, white space characters are ignored, and
all other characters are returned as-is.
Once a token is returned, d_column is updated to indicate the column
number of the last-matched character. To obtain the matched text's
initial column number, subtract length() - 1.
Here is a simple main function, reading its cin stream, and showing
lines, column indicators, line numbers, and column numbers of detected square
brackets:
#include <iostream>
#include <iomanip>
#include "scanner.h"
using namespace std;
int main()
{
Scanner scanner; // define a Scanner object
while (int token = scanner.lex()) // get all tokens
{
string const &text = scanner.matched();
switch (token)
{
case IDENTIFIER:
cout << "identifier: " << text << '\n';
break;
case NUMBER:
cout << "number: " << text << '\n';
break;
case SIGNAL:
{
cout <<
'\n' <<
scanner.line() << '\n' <<
setw(scanner.column()) << '^' << "\n"
"Line " << scanner.lineNr() << ", column " <<
scanner.column() <<
": saw `" << scanner.matched() << "'\n\n";
}
break;
default:
cout << "char. token: `" << text << "'\n";
break;
}
}
}
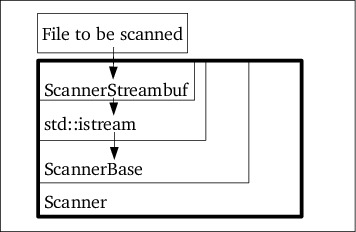
This approach uses multiple inheritance to add std::streambuf and
std::istream facilities to the class Scanner. However, these
facilities are for internal use only: they are merely used for wrapping the
std::istream that is actually passed to the scanner.
Once the set of files have been generated from the rules file (e.g.,
lexer) the file Scanner.h is available, and this file will be slightly
modified: we'll use triple inheritance for the class Scanner:
class Scanner: private ScannerStreambuf, private std::istream,
public ScannerBase
Only for the ScannerBase public inheritance is used: the initial two
classes are used to implement Scanner in terms of these classes. The class
IStreambuf is doing all the magic and is discussed below. The
std::istream base class receives ScannerStreambuf's address, turning
Scanner objects into std::istream objects, but only so for the benefit
of the Scanner object itself. ScannerBase, of course, is left
untouched.
The class ScannerStreambuf maintains and offers the contents of the
currently scanned line and column numbers of returned characters. The
Scanner's interface shares its members line and column to make
this information available to any class that may access the Scanner
object. To accomplish this the following declarations are added Scanner's
public interface:
using ScannerStreambuf::line;
using ScannerStreambuf::column;
The member explicit Scanner(std::istream &in = std::cin, std::ostream &out
= std::cout) now must make sure the ScannerStreambuf and std::istream
are properly initialized before the ScannerBase can be initialized.
the ScannerStreambuf is a wrapper around the actual std::istream, and
it receives the initial stream from the constructor's arguments. This
completes the ScannerStreambuf construction, making std::istream's
std::streambuffer available. The interesting part comes next: now that the
Scanner is an std::istream it can simply be passed to ScannerBase
as the input file to be processed (cf. figure 1).
The code implementing this organization looks like this:
Scanner::Scanner(std::istream &in, std::ostream &out)
:
ScannerStreambuf(cin),
istream(this),
ScannerBase(*this, cout)
{}
ScannerStreambuf uses two data members (d_line and
d_column) to store, respectively, the line that's currently being scanned
and the column to where the scanning process has proceeded. In addition it
needs access to the actual input stream (in this example only one stream is
used, so a std::istream &d_in can be used; if stream-switching should be
supported then use a std::istream *d_inPtr), and it uses a one-character
buffer (there's no real need to use a bigger buffer, as the input stream may
already define its own buffer, and the scanner merely reads its input one
character at the time anyway (through Input::get).
ScannerStreambuf only needs a very basic interface:
class ScannerStreambuf: public std::streambuf
{
std::istream &d_in;
std::string d_line;
size_t d_column = 0;
char d_ch;
public:
ScannerStreambuf(std::istream &in);
std::string const &line() const;
size_t column() const;
private:
int underflow() override;
};
The members line and column are simple accessors, returning,
respectively d_line and d_column. The constructor initializes d_in
and installs an empty buffer:
ScannerStreambuf::ScannerStreambuf(istream &in)
:
d_in(in)
{
setg(0, 0, 0);
}
The member underflow isn't complicated either: if all characters in
d_line have been processed (which is initially true) the next line is read
into d_line, adding a newline character to d_line.
Then the next character in d_line is assigned to d_ch, and the
input buffer is defined to point at d_ch. Here is its implementation:
int ScannerStreambuf::underflow()
{
if (d_column == d_line.length())
{
if (!getline(d_in, d_line))
return EOF;
d_column = 0;
d_line += '\n';
}
d_ch = d_line[d_column++];
setg(&d_ch, &d_ch, &d_ch + 1);
return *gptr();
}
%filenames scanner %% [ \t\n]+ // skip white space chars. [0-9]+ return NUMBER; [[:alpha:]_][[:alpha:][:digit:]_]* return IDENTIFIER; [][] return SIGNAL; . return matched()[0];
Identifiers and numbers are returned as tokens, square brackets are returned
as SIGNAL tokens, indicating that we would like to see the lines and
columns in which they were found, white space characters are ignored, and
all other characters are returned as-is.
The main function uses the column and line members, which were
added to the class Scanner:
int main()
{
ScannerStreambuf buf(cin);
istream in(&buf);
string line;
Scanner scanner(in); // define a Scanner object
while (int token = scanner.lex()) // get all tokens
{
string const &text = scanner.matched();
switch (token)
{
case IDENTIFIER:
cout << "identifier: " << text << '\n';
break;
case NUMBER:
cout << "number: " << text << '\n';
break;
case SIGNAL:
{
cout <<
'\n' <<
scanner.line() <<
setw(scanner.column()) << '^' << "\n"
"Line " << scanner.lineNr() << ", column " <<
scanner.column() <<
": saw `" << scanner.matched() << "'\n\n";
}
break;
default:
cout << "char. token: `" << text << "'\n";
break;
}
}
}
The IStreambuf wraps around cin, and is passed to an istream,
which in turn is passed to the Scanner object. When the scanner returns
SIGNAL tokens their lines, column indicators, line numbers and column
numbers are shown.
Members like switchStream and pushStream, expecting std::istream
references can also be used, if the actual input streams are wrapped in
ScannerStreambuf objects, which are passed to istream objects which
are, in turn, passed to switchStream and pushStream. The members
expecting names of streams should of course not be used, since the scanner
creates plain std::ifstream objects for them.